
AI systems don’t fail because of bad algorithms—they fail because of bad data.
In the Microsoft ecosystem, with tools like ML.NET, Azure Cognitive Services, and Azure Machine Learning, it’s easy to spin up models. But none of that matters if your data is incomplete, inconsistent, biased, mislabeled, or outdated.
Dirty data is silent. It doesn’t crash your app. It doesn’t throw errors. It just makes your AI… wrong. Quietly. Persistently. Expensively.
💸 The True Cost of Dirty Data
Dirty data creates invisible drag across every stage of an AI project:
- Wasted compute power from training on noise
- False predictions that mislead decision-makers
- Low adoption due to “off” or unreliable outputs
- Costly rework downstream
Gartner estimates poor data quality costs organizations $12.9M annually—and AI makes the stakes even higher.
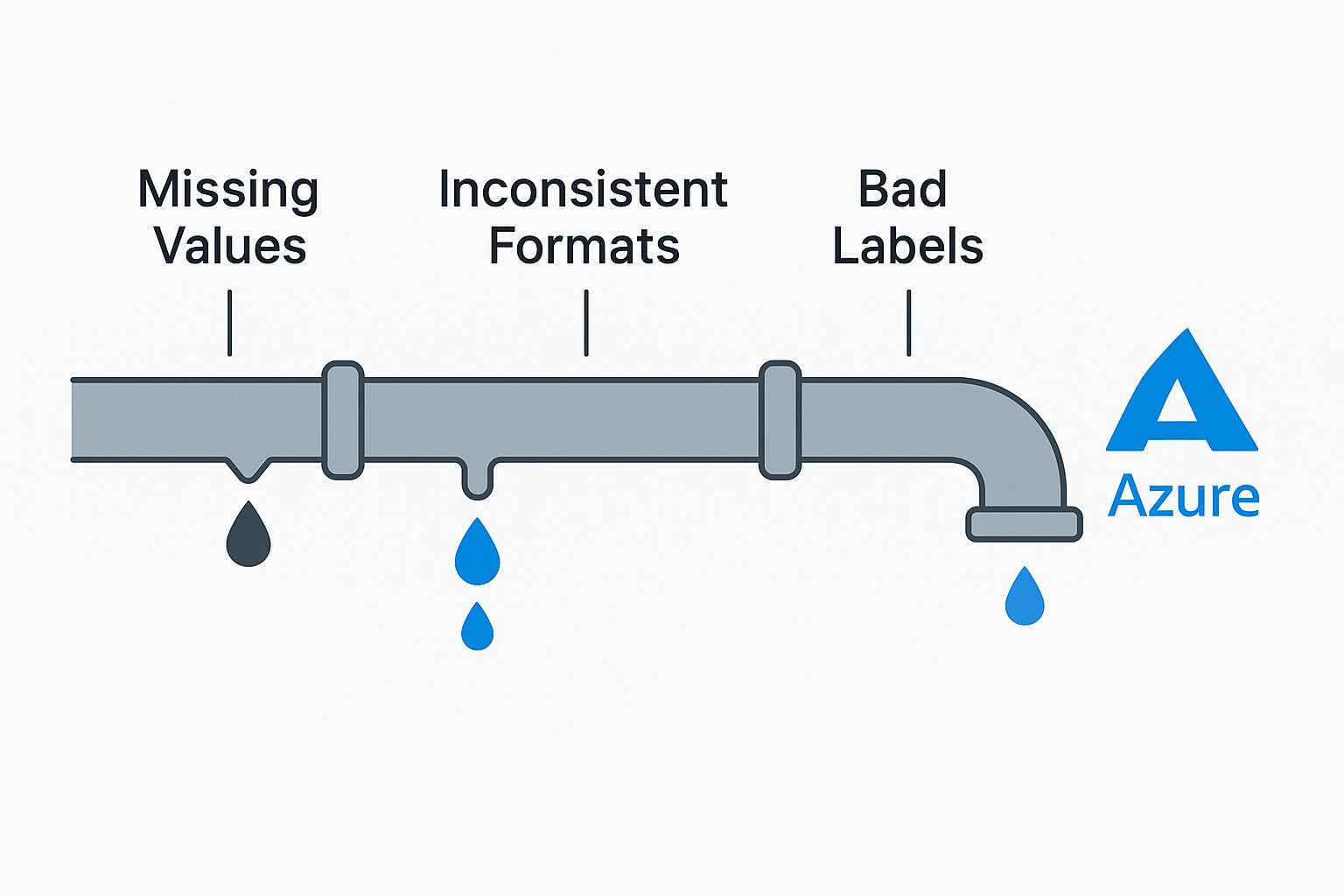
🔍 What Counts as Dirty Data?
| Problem Type | Microsoft AI Impact |
|---|---|
| Missing Values | Azure AutoML skips rows or inserts unreliable defaults |
| Inconsistent Formats | Time-series failure from misaligned date formats |
| Mislabeled Training | ML.NET learns incorrect classifications |
| Ambiguous Language | Sentiment misfire in Cognitive Services |
| Duplicates | Overrepresentation in training |
| Biased Sampling | Poor real-world generalization |
🛠️ Lessons from Microsoft AI Tools
✅ ML.NET
- Feature selection and label balance are everything.
- Pipelines (
IDataView) expose poor transformations.
✅ Azure Cognitive Services
- Performs best with clean, structured, preprocessed inputs.
- Poor signal (noise, slang, blur) = poor prediction.
✅ Azure Machine Learning
- Has great metadata tracking—but only works if your input is curated.
- Human labeling still matters.
✔️ How to Clean and Protect Your Data Pipeline
- Validate Early – Use
IDataView, Power Query, and DataFrame previews. - Normalize Consistently – Standardize formats, units, case, and null handling.
- Involve Domain Experts – Label and validate with context, not just code.
- Automate Checks – Nulls, outliers, drift, imbalance—test them all.
- Track Lineage – Use Azure ML Datasets + versioning to protect history.
🧠 Executive Insight
If your team is spending more time on models than on data, you’re doing it wrong.
80% of AI value comes from data engineering—not data science.
No Microsoft tool can fix what you didn’t detect.